Notes from the following sources:
http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2006/n2027.html
http://thbecker.net/articles/rvalue_references/section_01.html
An rvalue reference is formed by placing an && after some type.
A a;
A& a_ref1 = a; // an lvalue reference
A&& a_ref2 = a; // an rvalue reference
An rvalue reference behaves just like an lvalue reference except that it
can bind to a temporary (an rvalue), whereas you can not bind a (non const) lvalue reference to an rvalue. You can also bind a rvalue reference to a lvaue.
A& a_ref3 = A(); // Error!
A&& a_ref4 = A(); // Ok
An lvalue is an expression e that may appear on the left or on the right hand side of an assignment, whereas an rvalue is an expression that can only appear on the right hand side of an assignment. For example,
int a = 42;
int b = 43;
// a and b are both l-values:
a = b; // ok
b = a; // ok
a = a * b; // ok
// a * b is an rvalue:
int c = a * b; // ok, rvalue on right hand side of assignment
a * b = 42; // error, rvalue on left hand side of assignment
What we get from rvalue references is more general and better performing libraries.
Move Semantics
Eliminating spurious copies
Copying can be expensive. For example, for
std::vectors,
v2=v1 typically involves a function call, a memory allocation, and a loop. This is of course acceptable where we actually need two copies of a
vector, but in many cases, we don't: We often copy a
vector from one place to another, just to proceed to overwrite the old copy. Consider:
template <class T> swap(T& a, T& b)
{
T tmp(a); // now we have two copies of a
a = b; // now we have two copies of b
b = tmp; // now we have two copies of tmp (aka a)
}
But, we didn't want to have
any copies of
a or
b, we just wanted to swap them. Let's try again:
template <class T> swap(T& a, T& b)
{
T tmp(std::move(a));
a = std::move(b);
b = std::move(tmp);
}
This move() gives its target the value of its argument, but is not obliged to preserve the value of its source. So, for a vector, move() could reasonably be expected to leave its argument as a zero-capacity vector to avoid having to copy all the elements. In other words,move is a potentially destructive read.
In this particular case, we could have optimized swap by a specialization. However, we can't specialize every function that copies a large object just before it deletes or overwrites it. That would be unmanageable.
The first task of rvalue references is to allow us to implement move() without verbosity, or runtime overhead.
move
The move function really does very little work. All move does is accept either an lvalue or rvalue argument, and return it as an rvalue without triggering a copy construction:
template <class T>
typename remove_reference<T>::type&&
move(T&& a)
{
return a;
}
The functions that accept rvalue reference parameters (including move constructors, move assignment operators, and regular member functions such as std::vector::push_back) are selected, by overload resolution, when called with rvalue arguments (either prvalues such as a temporary objects or xvalues such as the one produced by std::move). If the argument identifies a resource-owning object, these overloads have the option, but aren't required, to move any resources held by the argument. For example, a move constructor of a linked list might copy the pointer to the head of the list and store NULL in the argument instead of allocating and copying individual nodes.
It is now up to client code to overload key functions on whether their argument is an lvalue or rvalue (e.g. copy constructor and assignment operator). When the argument is an lvalue, the argument must be copied from. When it is an rvalue, it can safely be moved from.
Return by value
Be honest: how does the following code make you feel?
std::vector<std::string> get_names();
…
std::vector<std::string> const names = get_names();
|
Frankly, even though I should know better, it makes me nervous. In principle, when get_names() returns, we have to copy a vector of strings. Then, we need to copy it again when we initialize names, and we need to destroy the first copy. If there are N strings in the vector, each copy could require as many as N+1 memory allocations and a whole slew of cache-unfriendly data accesses as the string contents are copied.
Rather than confront that sort of anxiety, I’ve often fallen back on pass-by-reference to avoid needless copies:
get_names(std::vector<std::string>& out_param );
…
std::vector<std::string> names;
get_names( names );
|
Unfortunately, this approach is far from ideal.
- The code grew by 150%
- We’ve had to drop
const-ness because we’re mutating names.
- As functional programmers like to remind us, mutation makes code more complex to reason about by undermining referential transparency and equational reasoning.
- We no longer have strict value semantics1 for
names.
Copy Elision and the RVO
The reason I kept writing above that copies were made “in principle” is that the compiler is actually allowed to perform some optimizations based on the same principles we’ve just discussed. This class of optimizations is known formally as copy elision. For example, in the Return Value Optimization (RVO), the calling function allocates space for the return value on its stack, and passes the address of that memory to the callee. The callee can then construct a return value directly into that space, which eliminates the need to copy from inside to outside. The copy is simply elided, or “edited out,” by the compiler.
Also, although the compiler is normally required to make a copy when a function parameter is passed by value (so modifications to the parameter inside the function can’t affect the caller), it is allowed to elide the copy, and simply use the source object itself, when the source is an rvalue.
Guideline: Don’t copy your function arguments. Instead, pass them by value and let the compiler do the copying. But if there is no copy involved in the function, it should be better to use const reference.
References:
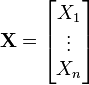 ,
,![\Sigma
= \begin{bmatrix}
\mathrm{E}[(X_1 - \mu_1)(X_1 - \mu_1)] & \mathrm{E}[(X_1 - \mu_1)(X_2 - \mu_2)] & \cdots & \mathrm{E}[(X_1 - \mu_1)(X_n - \mu_n)] \\ \\
\mathrm{E}[(X_2 - \mu_2)(X_1 - \mu_1)] & \mathrm{E}[(X_2 - \mu_2)(X_2 - \mu_2)] & \cdots & \mathrm{E}[(X_2 - \mu_2)(X_n - \mu_n)] \\ \\
\vdots & \vdots & \ddots & \vdots \\ \\
\mathrm{E}[(X_n - \mu_n)(X_1 - \mu_1)] & \mathrm{E}[(X_n - \mu_n)(X_2 - \mu_2)] & \cdots & \mathrm{E}[(X_n - \mu_n)(X_n - \mu_n)]
\end{bmatrix}.](http://upload.wikimedia.org/math/5/8/5/58572fa5b05e778f5a5eff9ec1b3ddb6.png)