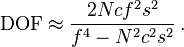In a supervised learning problem, we want to find the function f: X -> Y, or P(Y|X). Discriminative models directly estimate P(Y|X). It is given the name because given X, we can directly discriminate (or determine) the value of the target Y. Generative models, on the other hand, estimate the joint probability P(Y, X) by finding P(X|Y) and P(Y). It is called generative because given the parameters P(X|Y) and P(Y), we can generate observable samples from the model.
Discriminative models include: logistic regression, conditional random fields, support vector machine
Generative models include: HMM, naive Bayes, Gaussian mixture models.
For solving a classification problem, a discriminative classifier is almost always preferred because discriminative models do not need to model the distribution of the observed variables, and they can generally express more complex relationships between the observed and target variables. However,
Ng et al. also
demonstrated in their experiments that generative methods may also converge more quickly to its (higher) asymptotic error as number of training examples increases. The generative model may also approach its asymptotic error with a number of training examples that is only
logarithmic, rather than linear, in the number of
parameters. This means that with smaller number of training examples, generative models may do better.