Shortest path
Dijkstra: \(\Theta(V)\) inserts into priority queue, \(\Theta(V)\) EXTRACT_MIN operations, \(\Theta(E)\) DECREASE_KEY operations.Min-heap implementation: \(\Theta((V + E)\log V)\)
Fibonacci heap implementation: \(\Theta(\log V)\) for exact min, \(\Theta(1)\) for decrease key and insertion, total amortized cost \(\Theta(V\log V + E)\)
Fibonacci heap
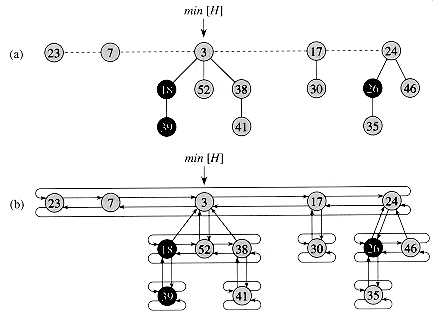
A list of heap-ordered trees. We access the heap by a pointer to the tree root with the overall minimum key.
Main operations
Inserting a node: create a new tree containing only x and insert it into the root list of H.Decrease-key: cut the node from its parent, then insert the node into the root list with a new key. \(O(1)\)
Delete-min: remove the root of the smallest key, add its children to the root-list, and scan through the linked list of all the root nodes to find the new root of minimum key. We also need need to consolidate the root list by merging roots with the same degree (same number of children). We can think of consolidation as allocating buckets of size up to the maximum possible rank for any root node, which is O(log n). We put each node into the appropriate bucket and march through the buckets, starting at the smallest one, and consolidate everything possible. Therefore the cost of delete-min operation is O(# of children) of the root of the minimum key plus O(# of root nodes).
Population control for roots
We want to make sure that every node has a small number of children. This can be done by ensuring that the total number of descendants of any node is exponential in the number of its children. One way to do this is by only merging trees that have the same number of children (degree).
\begin{align}
size(x) &\ge s_k \\
& \ge 2 + \sum_{i = 2}^k s_{y_i.degree} \\
& \ge 2 + \sum_{i = 2}^k s_{i - 2} \\
& \ge 2 + \sum_{i = 2}^k F_i \; \text{(by induction)}\\
& = 1 + \sum_{i = 0}^k F_i \\
& = F_{k + 2}\\
&\ge \phi^k
\end{align}
Fibonacci numbers
\begin{align}F_0 &= 0, \\
F_1 &= 1, \\
F_i &= F_{i - 1} + F_{i - 2} \;\text{for } i \ge 2.
\end{align}
