An HMM is a stochastic finite automaton, where each state generates an observation. The observation can be a discrete symbol or a feature vector. The parameters of the model are the initial state distribution, the transition model, and the observation model. An HMM can be represented by a state transition diagram or by a Bayesian network.
Any HHMM can be converted to HMM. The resulting state-space may be smaller, because it does not contain abstract states. This occurs if there are not many shared sub-structures. The state-space may be larger if there are shared sub-structures because they must be duplicated. Whether the state-space will be lager or smaller, depends on the ratio between the number of hidden states \(n_h^S\) in HHMM and the number of hidden states \(n^S\) in HMM.
In general, a dynamic Bayesian network (DBN) can be converted to an HMM if all the hidden nodes are discrete. In this case, using the HMM inference engine can be faster than the using the junction tree inference engine for small models because the constant factors of the algorithm are lower, but can be exponentially slower for models with many variables (e.g., > 6 binary hidden nodes).
HMM parameter learning: EM algorithm
n sequences with length m
\begin{align}
t^t(s'|s) = \frac{\sum_{i = 1}^n\sum_{j=1}^m p(S_j = s, S_{j+1} = s'|x_{i, 1}\ldots x_{i, m};\underline{\theta})}{\sum_{i = 1}^n\sum_{j=1}^m \sum_{s'} p(S_j = s, S_{j+1} = s'|x_{i, 1}\ldots x_{i, m};\underline{\theta})}
\end{align}
$$\sum_{s'} t(s'|s) = 1$$
Monday, 8 July 2013
Sunday, 7 July 2013
Ruby on Rails
Association
Auto-generated methods
Singular associations (one-to-one)
| | belongs_to |
generated methods | belongs_to | :polymorphic | has_one
----------------------------------+------------+--------------+---------
#other | X | X | X
#other=(other) | X | X | X
#build_other(attributes={}) | X | | X
#create_other(attributes={}) | X | | X
#other.create!(attributes={}) | | | X
#other.nil? | X | X |
Collection associations (one-to-many / many-to-many)
| | | has_many
generated methods | habtm | has_many | :through
----------------------------------+-------+----------+----------
#others | X | X | X
#others=(other,other,...) | X | X | X
#other_ids | X | X | X
#other_ids=(id,id,...) | X | X | X
#others<< | X | X | X
#others.push | X | X | X
#others.concat | X | X | X
#others.build(attributes={}) | X | X | X
#others.create(attributes={}) | X | X | X
#others.create!(attributes={}) | X | X | X
#others.size | X | X | X
#others.length | X | X | X
#others.count | X | X | X
#others.sum(args*,&block) | X | X | X
#others.empty? | X | X | X
#others.clear | X | X | X
#others.delete(other,other,...) | X | X | X
#others.delete_all | X | X |
#others.destroy_all | X | X | X
#others.find(*args) | X | X | X
#others.find_first | X | |
#others.uniq | X | X | X
#others.reset | X | X | X
Auto-generated methods
Singular associations (one-to-one)
| | belongs_to |
generated methods | belongs_to | :polymorphic | has_one
----------------------------------+------------+--------------+---------
#other | X | X | X
#other=(other) | X | X | X
#build_other(attributes={}) | X | | X
#create_other(attributes={}) | X | | X
#other.create!(attributes={}) | | | X
#other.nil? | X | X |
Collection associations (one-to-many / many-to-many)
| | | has_many
generated methods | habtm | has_many | :through
----------------------------------+-------+----------+----------
#others | X | X | X
#others=(other,other,...) | X | X | X
#other_ids | X | X | X
#other_ids=(id,id,...) | X | X | X
#others<< | X | X | X
#others.push | X | X | X
#others.concat | X | X | X
#others.build(attributes={}) | X | X | X
#others.create(attributes={}) | X | X | X
#others.create!(attributes={}) | X | X | X
#others.size | X | X | X
#others.length | X | X | X
#others.count | X | X | X
#others.sum(args*,&block) | X | X | X
#others.empty? | X | X | X
#others.clear | X | X | X
#others.delete(other,other,...) | X | X | X
#others.delete_all | X | X |
#others.destroy_all | X | X | X
#others.find(*args) | X | X | X
#others.find_first | X | |
#others.uniq | X | X | X
#others.reset | X | X | X
Saturday, 6 July 2013
Trianglulate a graph
Triangulation ensures a graph G is triangulated (chordal), i.e., every cycle of length > 3 has a chord. During the process, we can also find maximal cliques in the triangulated graph.
Pseudo code:
// G is moralized.
triangulate(G, order):
1. eliminated = {}
2. cliques = {}
3. for i = 1 : n
u = order(i)
nodes = neighbors of u which are not eliminated yet \(\cup\) u
make every node in nodes all connected to each other
add u to eliminated
check whether nodes is a subset of any clique already found, if not, add nodes to cliques.
Pseudo code:
// G is moralized.
triangulate(G, order):
1. eliminated = {}
2. cliques = {}
3. for i = 1 : n
u = order(i)
nodes = neighbors of u which are not eliminated yet \(\cup\) u
make every node in nodes all connected to each other
add u to eliminated
check whether nodes is a subset of any clique already found, if not, add nodes to cliques.
Tuesday, 2 July 2013
Algorithm complexity
http://bigocheatsheet.com
Min-heap implementation: \(\Theta((V + E)\log V)\)
Fibonacci heap implementation: \(\Theta(\log V)\) for exact min, \(\Theta(1)\) for decrease key and insertion, total amortized cost \(\Theta(V\log V + E)\)
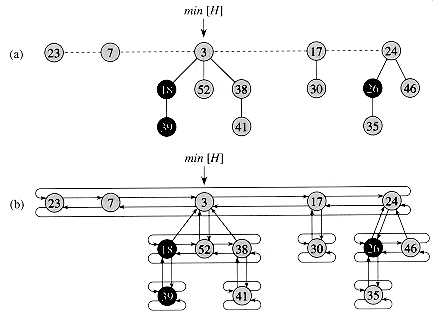
A list of heap-ordered trees. We access the heap by a pointer to the tree root with the overall minimum key.
Decrease-key: cut the node from its parent, then insert the node into the root list with a new key. \(O(1)\)
Delete-min: remove the root of the smallest key, add its children to the root-list, and scan through the linked list of all the root nodes to find the new root of minimum key. We also need need to consolidate the root list by merging roots with the same degree (same number of children). We can think of consolidation as allocating buckets of size up to the maximum possible rank for any root node, which is O(log n). We put each node into the appropriate bucket and march through the buckets, starting at the smallest one, and consolidate everything possible. Therefore the cost of delete-min operation is O(# of children) of the root of the minimum key plus O(# of root nodes).
Let \(s_k\) be the minimum size of any node of degree k in any Fibonacci heap. Let \(y_1, y_2, \ldots, y_k\) denote the children of x in the order in which they were linked to x
\begin{align}
size(x) &\ge s_k \\
& \ge 2 + \sum_{i = 2}^k s_{y_i.degree} \\
& \ge 2 + \sum_{i = 2}^k s_{i - 2} \\
& \ge 2 + \sum_{i = 2}^k F_i \; \text{(by induction)}\\
& = 1 + \sum_{i = 0}^k F_i \\
& = F_{k + 2}\\
&\ge \phi^k
\end{align}
F_0 &= 0, \\
F_1 &= 1, \\
F_i &= F_{i - 1} + F_{i - 2} \;\text{for } i \ge 2.
\end{align}
Shortest path
Dijkstra: \(\Theta(V)\) inserts into priority queue, \(\Theta(V)\) EXTRACT_MIN operations, \(\Theta(E)\) DECREASE_KEY operations.Min-heap implementation: \(\Theta((V + E)\log V)\)
Fibonacci heap implementation: \(\Theta(\log V)\) for exact min, \(\Theta(1)\) for decrease key and insertion, total amortized cost \(\Theta(V\log V + E)\)
Fibonacci heap
A list of heap-ordered trees. We access the heap by a pointer to the tree root with the overall minimum key.
Main operations
Inserting a node: create a new tree containing only x and insert it into the root list of H.Decrease-key: cut the node from its parent, then insert the node into the root list with a new key. \(O(1)\)
Delete-min: remove the root of the smallest key, add its children to the root-list, and scan through the linked list of all the root nodes to find the new root of minimum key. We also need need to consolidate the root list by merging roots with the same degree (same number of children). We can think of consolidation as allocating buckets of size up to the maximum possible rank for any root node, which is O(log n). We put each node into the appropriate bucket and march through the buckets, starting at the smallest one, and consolidate everything possible. Therefore the cost of delete-min operation is O(# of children) of the root of the minimum key plus O(# of root nodes).
Population control for roots
We want to make sure that every node has a small number of children. This can be done by ensuring that the total number of descendants of any node is exponential in the number of its children. One way to do this is by only merging trees that have the same number of children (degree).
\begin{align}
size(x) &\ge s_k \\
& \ge 2 + \sum_{i = 2}^k s_{y_i.degree} \\
& \ge 2 + \sum_{i = 2}^k s_{i - 2} \\
& \ge 2 + \sum_{i = 2}^k F_i \; \text{(by induction)}\\
& = 1 + \sum_{i = 0}^k F_i \\
& = F_{k + 2}\\
&\ge \phi^k
\end{align}
Fibonacci numbers
\begin{align}F_0 &= 0, \\
F_1 &= 1, \\
F_i &= F_{i - 1} + F_{i - 2} \;\text{for } i \ge 2.
\end{align}
Fourier transformation
The convolution integral
Harmonic signals (complex exponential) are eigenfunctions for LTI systems. That is,
\[\mathcal{H}f = \lambda f\].
Suppose the input is \(x(t) = Ae^{st}\). The output of the system with impulse repose h(t) is then
\begin{align}\int_{-\infty}^\infty h(t-\tau)Ae^{s\tau}d\tau & = \int_{-\infty}^{\infty}h(\tau)Ae^{s(t-\tau)}d\tau = Ae^{st}\int_{-\infty}^{\infty}h(\tau)e^{-s\tau}d\tau \\ & =Ae^{st}H(s)\end{align}
where H(s) is a scalar dependent only on the parameter s.
Fourier series
Continuous time
\[X[k] = \frac{1}{T}\int_0^Tx(t)e^{-jk\omega_0t}dt\]
Discrete time
\[X[k] = \frac{1}{N}\sum_{n=<N>}x[n]e^{-jk\Omega_0n}\]
- The output y(t) to an input x(t) is seen as a weighted superposition of impulse response time-shifted by \(\tau\).
- The expression is called the convolution integral and denoted by the same symbol * as in the discrete-time case\[y(t) = \int_{-\infty}^\infty x(\tau)h(t-\tau)d\tau = x(t)*h(t)\]
Harmonic signals (complex exponential) are eigenfunctions for LTI systems. That is,
\[\mathcal{H}f = \lambda f\].
Suppose the input is \(x(t) = Ae^{st}\). The output of the system with impulse repose h(t) is then
\begin{align}\int_{-\infty}^\infty h(t-\tau)Ae^{s\tau}d\tau & = \int_{-\infty}^{\infty}h(\tau)Ae^{s(t-\tau)}d\tau = Ae^{st}\int_{-\infty}^{\infty}h(\tau)e^{-s\tau}d\tau \\ & =Ae^{st}H(s)\end{align}
where H(s) is a scalar dependent only on the parameter s.
Fourier series
Continuous time
\[X[k] = \frac{1}{T}\int_0^Tx(t)e^{-jk\omega_0t}dt\]
Discrete time
\[X[k] = \frac{1}{N}\sum_{n=<N>}x[n]e^{-jk\Omega_0n}\]
Subscribe to:
Comments
(
Atom
)